





清华打造足球AI:首次实现同时控制10名球员完成比赛,胜率94.4%
2021-11-10 13:27:00
文章来自 | 量子位
丰色 发自 凹非寺量子位 报道 | 公众号 QbitAI
“只见4号球员在队友的配合下迅速攻破后防,单刀直入,一脚射门,球,进了!”
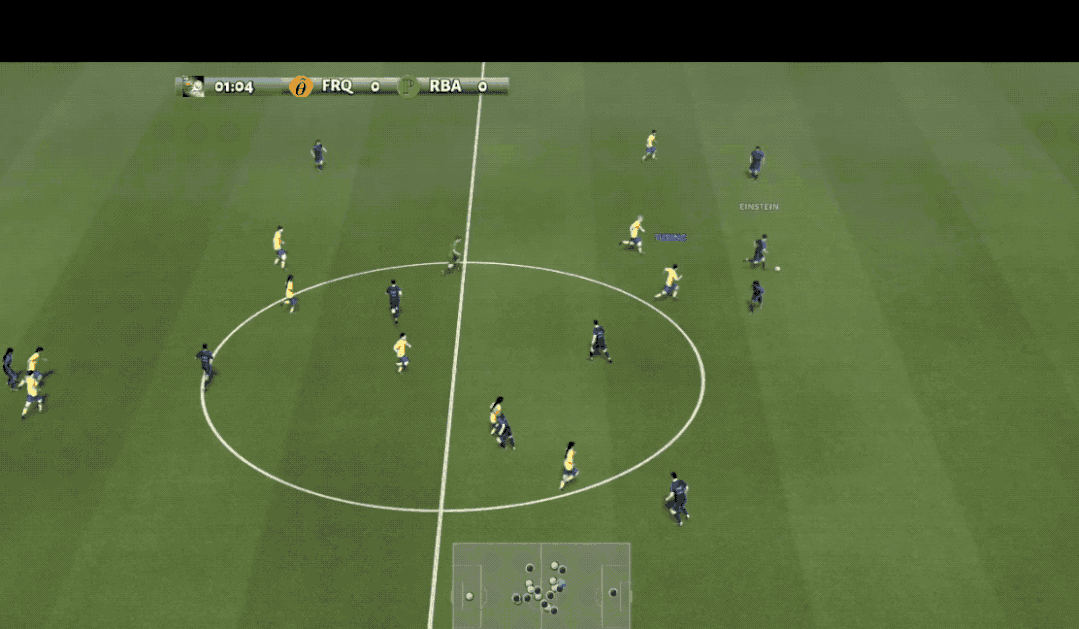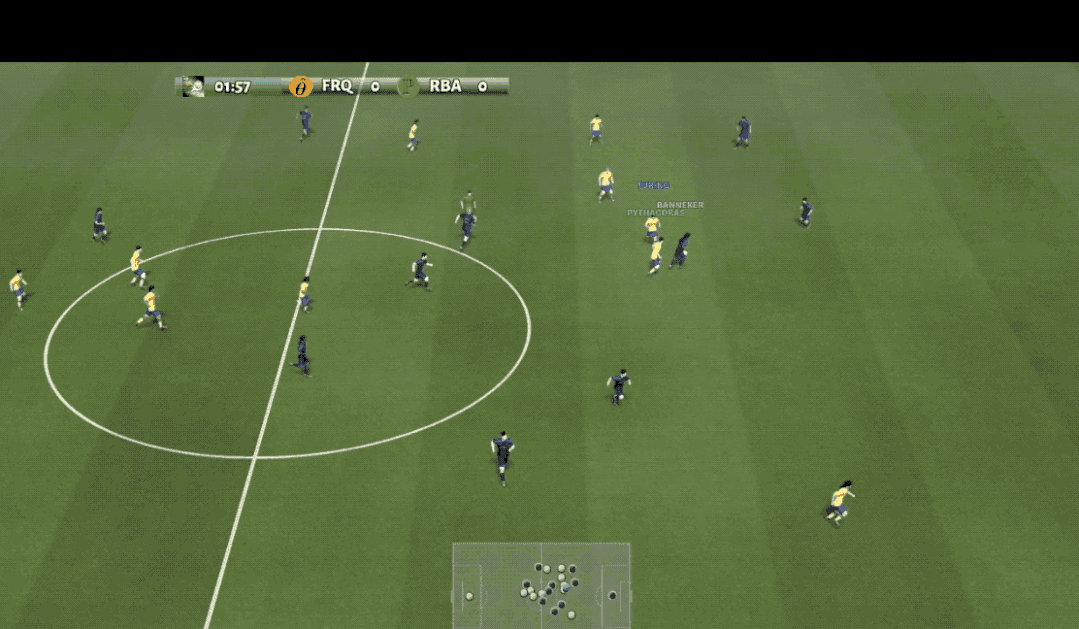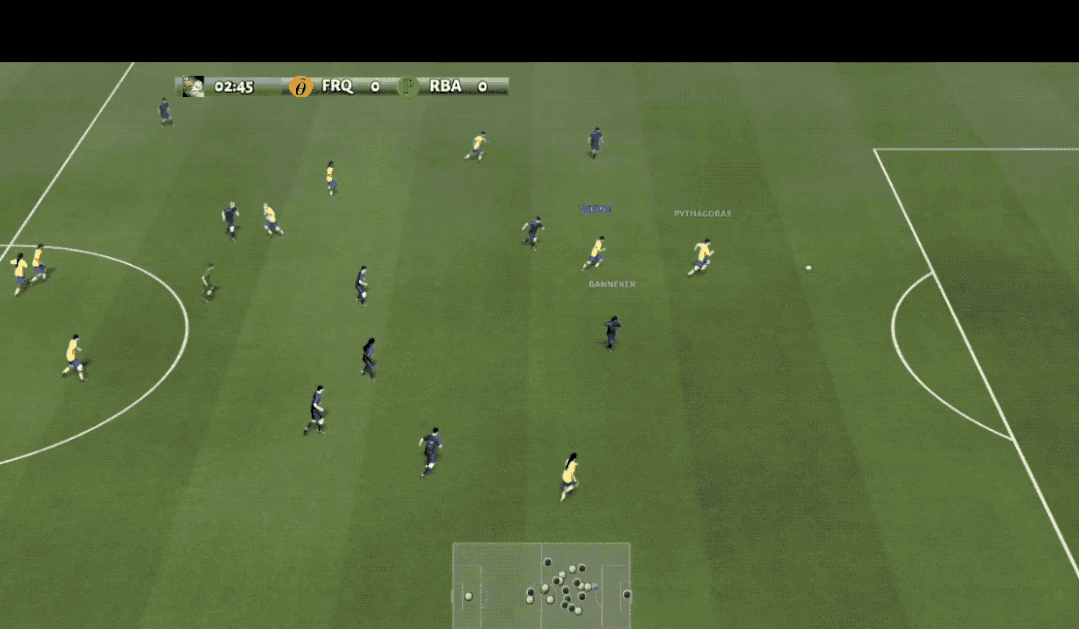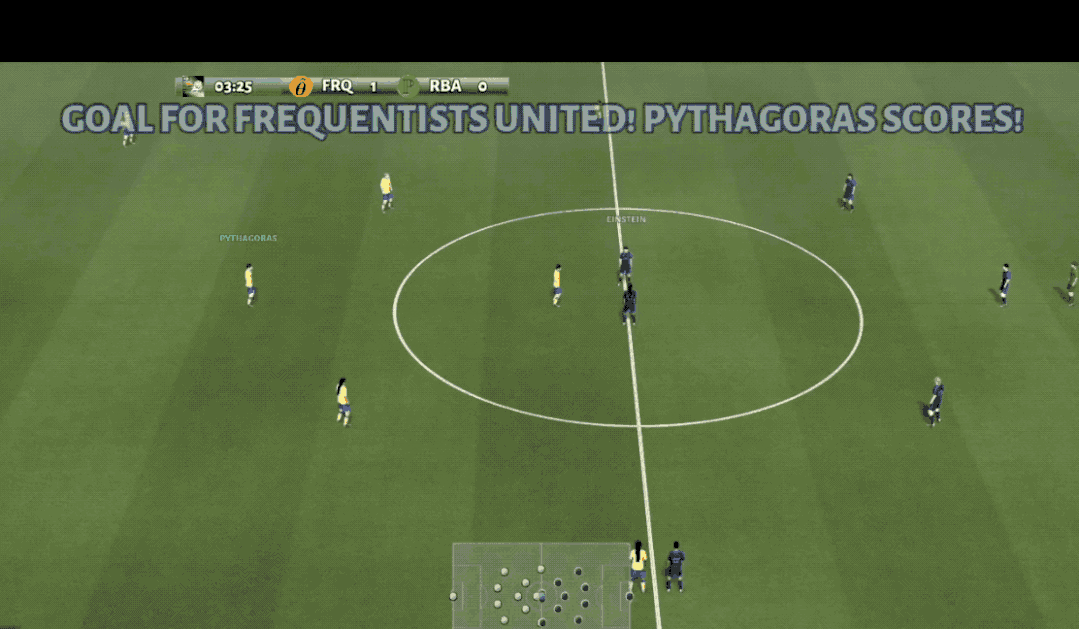
观众朋友们大家好,您现在看到的是谷歌AI足球比赛的现场,场上身着黄色球衣的是来自清华大学的AI球员。
这届清华AI可不一般,他们在艰苦训练之下,不仅有个人能力突出的明星球员,也有世界上最强最紧密的团队合作。
在多项国际比赛中所向披靡,夺得冠军。
“Oh,现在7号接过队友传来的助攻,临门一脚,球又进了!”

言归正传,以上其实是清华大学在足球游戏中打造的一个强大的多智能体强化学习AI——TiKick。
在多项国际赛事中夺得冠军则是指,TiKick在单智能体控制和多智能体控制上均取得了SOTA性能,并且还是首次实现同时操控十个球员完成整个足球游戏。
这支强大的AI团队是如何训练出来的呢?
从单智能体策略中进化出的多智能体足球AI
在此之前,先简单了解一下训练所用的强化学习环境,也就是这个足球游戏:Google Research Football(GRF)。
它由谷歌于2019年发布,提供基于物理的3D足球模拟,支持所有主要的比赛规则,由智能体操控其中的一名或多名足球运动员与另一方内置AI对战。
在由三千步组成的上下半场比赛中,智能体需要不断决策出移动、传球、射门、盘球、铲球、冲刺等19个动作完成进球。
在这样的足球游戏环境中进行强化学习难度有二:
一是因为多智能体环境,也就是一共10名球员(不含守门员)可供操作,算法需要在如此巨大的动作空间中搜索出合适的动作组合;
二是大家都知道足球比赛中一场进球数极少,算法因此很难频繁获得来自环境的奖励,训练难度也就大幅增大。
而清华大学此次的目标是控制多名球员完成比赛。
他们先从Kaggle在2020年举办的GRF世界锦标赛中,观摩了最终夺得冠军的WeKick团队数万场的自我对弈数据,使用离线强化学习方法从中学习。
这场锦标赛只需控制场中的一名球员进行对战。
如何从单智能体数据集学习出多智能体策略呢?
直接学习WeKick中的单智能体操作并复制到每个球员身上显然不可取,因为这样大家都只会自顾自地去抢球往球门冲,根本就不会有团队配合。
又没有后场非活跃球员动作的数据,那怎么办?
他们在动作集内添加了第二十个动作:build-in,并赋予所有非活跃球员此标签(比赛中若选用build-in作为球员的动作,球员会根据内置规则采取行动)。
接着采用多智能体行为克隆(MABC)算法训练模型。
对于离线强化学习来说,最核心的思想是找出数据中质量较高的动作,并加强对这些动作的学习。
所以需在计算目标函数时赋予每个标签不同的权重,防止球员倾向于只采用某个动作作为行动。
这里的权重分配有两点考虑:
一是从数据集中挑选出进球数较多的比赛、只利用这些高质量的数据来训练,由于奖励较为密集,模型能够加速收敛并提高性能。
二是训练出Critic网络给所有动作打分,并利用其结果计算出优势函数,然后给予优势函数值大的动作较高的权重,反之给予较低的权重。
此处为了避免梯度爆炸与消失,对优势函数做出了适当的裁剪。
最终的分布式训练架构由一个Learner与多个Worker构成。
其中Learner负责学习并更新策略,而Worker负责搜集数据,它们通过gRPC进行数据、网络参数的交换与共享。

Worker可以利用多进程的方式同时与多个游戏环境进行交互,或是通过I/O同步读取离线数据。
这种并行化的执行方式,也就大幅提升了数据搜集的速度,从而提升训练速度 (5小时就能达到别的分布式训练算法两天才能达到的同等性能)。
��外,通过模块化设计,该框架还能在不修改任何代码的情况下,一键切换单节点调试模式和多节点分布式训练模式,大大降低算法实现和训练的难度。
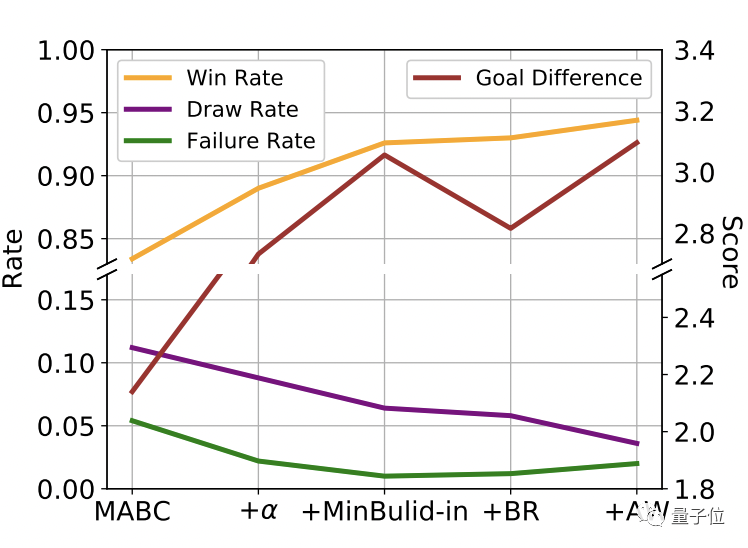
94.4%的获胜率和场均3分的净胜分
在多智能体(GRF)游戏上的不同算法比较结果中,TiKick的最终算法(+AW)以最高的获胜率(94.4%)和最大的目标差异达到了最佳性能。
TrueSkill(机器学习中竞技类游戏的排名系统)得分也是第一。

TiKick与内置AI的对战分别达到了94.4%的胜率和场均3分的净胜分。
将TiKick与GRF学术场景中的基线算法进行横向比较后发现,TiKick在所有场景下都达到了最佳性能和最低的样本复杂度,且差距明显。

与其中的基线MAPPO相比还发现,在五个场景当中的四个场景都只需100万步就能达到最高分数。

文章仅代表作者独立观点,不代表差评立场

评论
暂无评论